OCRFlux
综合介绍
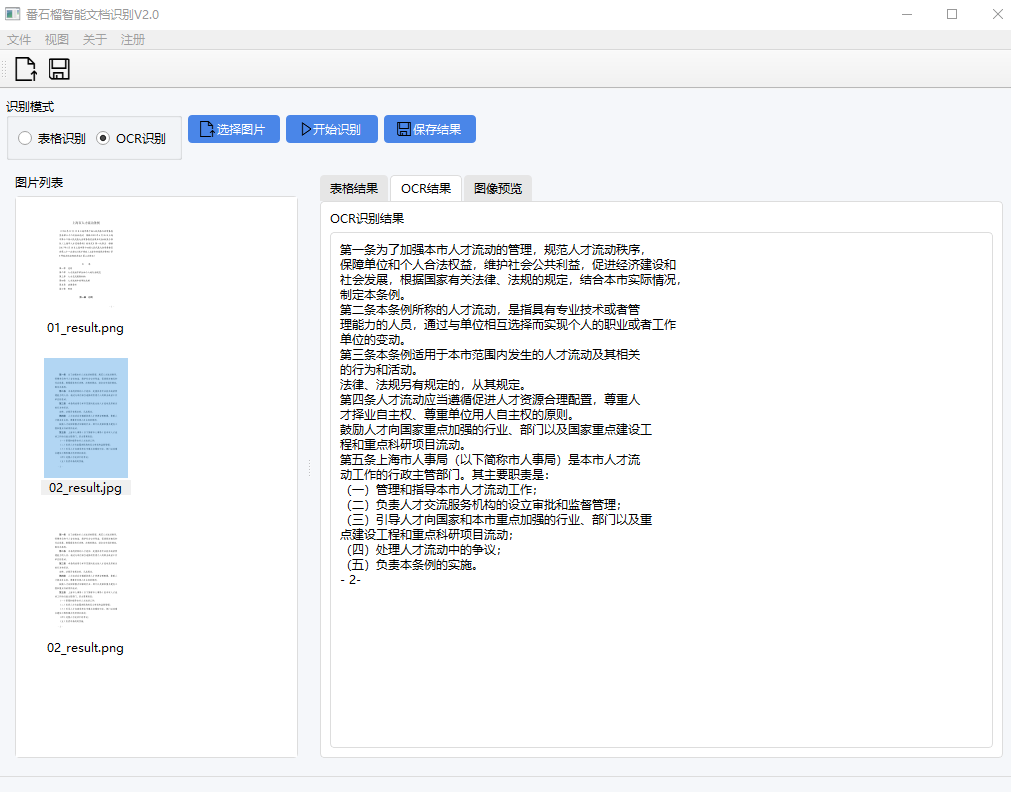
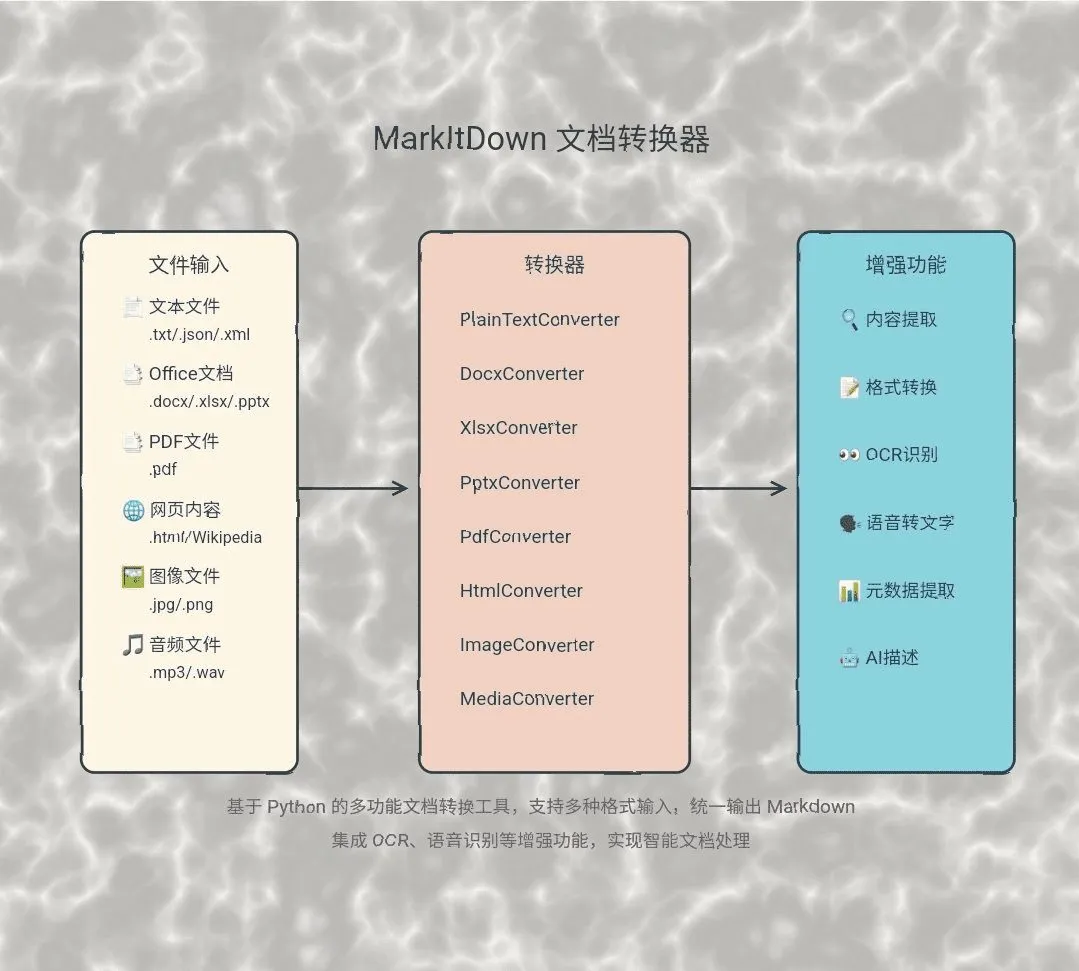
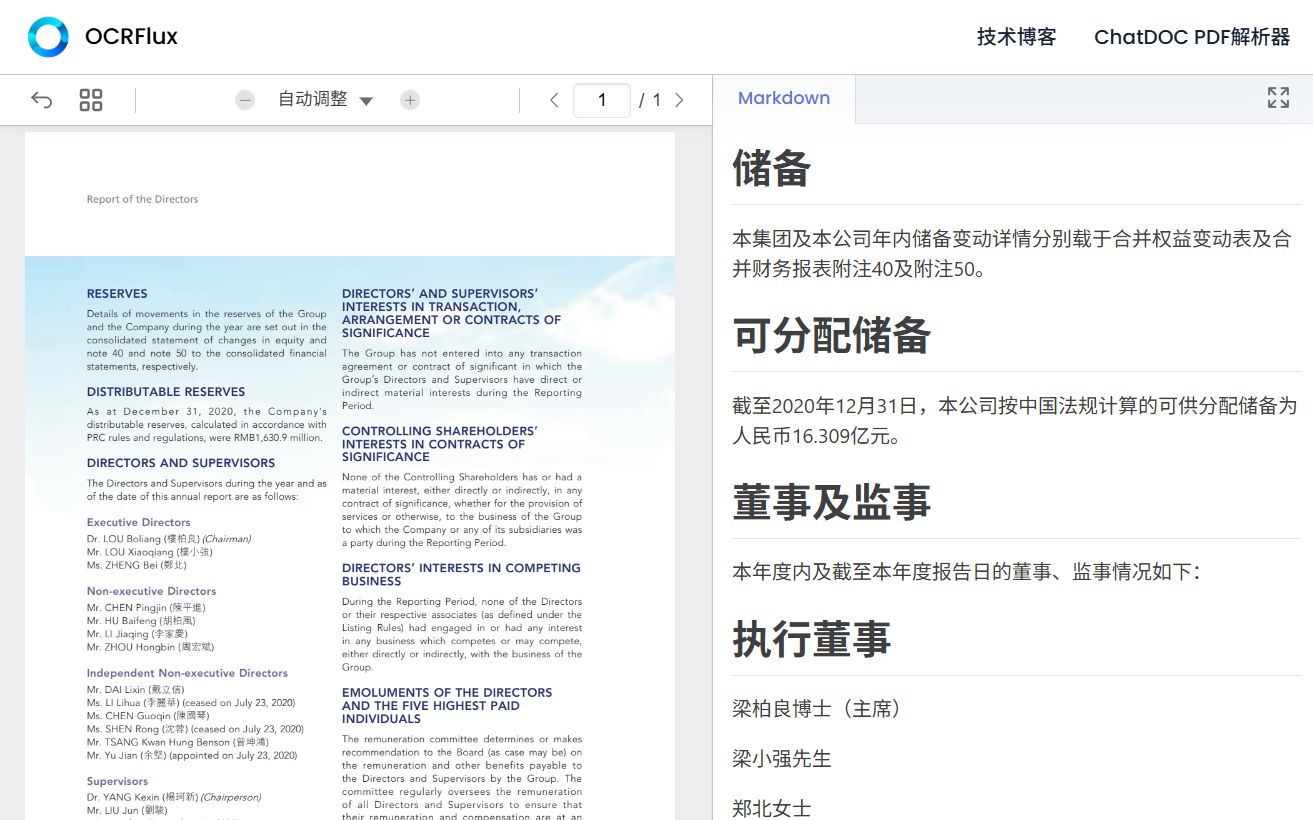
OCRFlux 是一个多模态工具包,主要功能是将PDF和图像文件转换为清晰、可读的Markdown文本。它的特点在于能够处理复杂的页面布局、解析高难度表格以及合并跨页内容。传统的PDF转文字工具在遇到多栏、图文混排或者跨页的表格和段落时,常常会出现格式混乱、内容丢失的问题。OCRFlux通过一个3B参数的视觉语言模型(VLM),能够更好地理解文档的结构和内容,从而生成格式正确、阅读顺序自然的Markdown文件。这个模型足够轻量,可以在普通的消费级显卡(如GTX 3090)上运行,降低了使用门槛。该项目由ChatDOC团队开发和维护,并在Apache 2.0许可下开源,这意味着任何人都可以免费使用和修改它。
功能列表
- 全文件解析: 将整个PDF文件,包括其中的多栏布局、图表、公式等复杂元素,转换为符合自然阅读顺序的文本。
- 自动页眉页脚移除: 在转换过程中自动识别并删除页面顶部的页眉和底部的页脚,使输出内容更干净。
- 复杂表格解析: 能够准确识别和解析包含复杂合并单元格(跨行、跨列)的表格,并将其转换为Markdown表格格式。
- 跨页内容合并:
- 跨页表格合并: 当一个大表格被分页截断时,能够自动识别并在最终的Markdown文件中将其合并成一个完整的表格。
- 跨页段落合并: 如果一个段落被分页符打断,能够将它们无缝地连接起来,保证段落的完整性。
- 多种使用方式:
- 支持通过命令行直接处理本地的PDF、图片或整个文件夹。
- 提供API接口,方便开发者在自己的代码中直接调用OCRFlux进行文件解析。
- 支持本地部署为服务,通过HTTP请求来进行文件解析。
- Docker支持: 提供了Docker镜像,用户可以在容器化环境中轻松部署和使用。
使用帮助
OCRFlux的安装和使用需要一定的技术背景,主要是面向开发者和有一定命令行操作经验的用户。以下是详细的安装和使用流程:
环境要求
在开始安装前,请确保你的系统满足以下条件:
- GPU: 一块近期的NVIDIA显卡,例如RTX 3090、4090、A100等,并且至少有12GB的显存。
- 磁盘空间: 至少20GB的可用磁盘空间,用于存放模型和处理文件。
- 操作系统: 推荐使用Linux发行版,如Ubuntu或Debian。
安装步骤
- 安装系统依赖:OCRFlux需要
poppler工具来处理PDF文件,同时需要一些额外的字体来正确渲染PDF中的内容。在Ubuntu或Debian系统上,可以通过以下命令安装:sudo apt-get update sudo apt-get install poppler-utils poppler-data ttf-mscorefonts-installer msttcorefonts fonts-crosextra-caladea fonts-crosextra-carlito gsfonts lcdf-typetools - 创建独立的Python环境:为了避免与系统中已有的Python库产生冲突,强烈建议使用
conda创建一个新的虚拟环境来安装OCRFlux。conda create -n ocrflux python=3.11 conda activate ocrflux - 克隆项目并安装:从GitHub上克隆OCRFlux的源代码,并进入项目目录进行安装。
git clone https://github.com/chatdoc-com/OCRFlux.git cd OCRFlux pip install -e . --find-links https://flashinfer.ai/whl/cu124/torch2.5/flashinfer/注意: 安装过程中会自动下载和安装所有需要的Python依赖库。
本地使用方法
安装完成后,你可以通过不同的方式来使用OCRFlux。首先,你需要下载预训练好的模型文件OCRFlux-3B。
1. 命令行直接解析文件
这是最基本的使用方式,适合快速测试或处理少量文件。
- 解析单个PDF文件:
python -m ocrflux.pipeline ./localworkspace --data test.pdf --model /path/to/OCRFlux-3B ``` - ` ./localworkspace`: 指定一个工作目录,用于存放中间文件和最终结果。 - `--data test.pdf`: 指定要处理的PDF文件路径。 - `--model /path/to/OCRFlux-3B`: 指定你下载的模型文件所在的路径。 - 解析单个图片文件:
python -m ocrflux.pipeline ./localworkspace --data test_page.png --model /path/to/OCRFlux-3B - 解析一个文件夹内的所有文件:
python -m ocrflux.pipeline ./localworkspace --data test_pdf_dir/* --model /path/to/OCRFlux-3B
处理完成后,结果会以JSONL的格式保存在./localworkspace/results目录下。每一行是一个JSON对象,包含了原始路径、页数、完整的Markdown文本等信息。
2. 在Python代码中作为API调用
如果你想在自己的程序中集成OCRFlux的功能,可以使用它提供的API。
from vllm import LLM
from ocrflux.inference import parse
# 加载模型
llm = LLM(model="/path/to/OCRFlux-3B", gpu_memory_utilization=0.8, max_model_len=8192)
# 指定要解析的文件路径
file_path = 'test.pdf'
# 调用解析函数
result = parse(llm, file_path)
if result:
document_markdown = result['document_text']
print(document_markdown)
with open('test.md', 'w') as f:
f.write(document_markdown)
else:
print("解析失败。")
这种方式更加灵活,你可以直接在代码中获取解析结果并进行后续处理。
3. 本地部署为服务
对于需要频繁处理大量文件的场景,可以把OCRFlux部署成一个本地服务,然后通过API请求来调用。
- 启动服务:项目提供了一个便捷的脚本来启动服务。
bash ocrflux/server.sh ChatDOC/OCRFlux-3B 30024这个命令会在本地的
30024端口启动一个vLLM服务。 - 发送请求:服务启动后,你可以使用
client.py脚本来发送解析请求。import asyncio from argparse import Namespace from ocrflux.client import request args = Namespace( model="/path/to/OCRFlux-3B", skip_cross_page_merge=False, max_page_retries=1, url="http://localhost", port=30024, ) file_path = 'test.pdf' result = asyncio.run(request(args, file_path)) if result: document_markdown = result['document_text'] print(document_markdown) with open('test.md', 'w') as f: f.write(document_markdown) else: print("解析失败。")
查看最终结果
无论使用哪种方式,处理结果首先会保存在JSONL文件中。你需要运行以下命令,将这些JSONL文件转换成最终用户可读的Markdown文件:
python -m ocrflux.jsonl_to_markdown ./localworkspace
生成的Markdown文件会存放在./localworkspace/markdowns/目录下,每个原始文件对应一个子目录。
应用场景
- 学术研究研究人员经常需要处理大量的PDF格式的论文。使用OCRFlux,可以将这些论文快速转换为Markdown格式,方便进行笔记、引用和内容整合。特别是对于包含复杂公式和表格的论文,OCRFlux能够保持其原有的结构,极大地提高了文献处理的效率。
- 知识库构建企业或个人在构建内部知识库时,往往有大量的历史文档(如产品手册、技术白皮书、报告等)是PDF格式。通过OCRFlux,可以批量将这些文档转换为易于搜索和编辑的Markdown格式,并导入到Notion、Obsidian等知识管理工具中,方便团队成员查阅和利用。
- 数据提取与分析对于金融、法律等行业,需要从财报、合同等PDF文档中提取大量的表格数据进行分析。OCRFlux强大的表格解析功能,尤其是跨页表格合并功能,可以准确地提取出完整的表格数据,为后续的数据分析工作提供干净、结构化的数据源。
- 内容创作与重组内容创作者或编辑需要从多个PDF文档中摘取信息进行整合和再创作。OCRFlux可以将这些PDF文档转换为易于复制和编辑的Markdown文本,创作者可以方便地在文本编辑器中对内容进行重组、修改和发布,而无需在PDF阅读器和编辑器之间来回切换。
QA
- OCRFlux支持哪些语言?根据其在GitHub上发布的评测基准,OCRFlux目前明确支持中文和英文文档的解析,并且在这两种语言上都取得了很高的准确率。
- 处理一个PDF文件大概需要多长时间?处理时间取决于PDF的页数、内容的复杂程度以及你使用的GPU性能。因为底层使用了
vllm进行推理,速度相对较快。但对于几百页的长文档,仍然可能需要几分钟的时间。 - 如果我的GPU显存不足12GB,可以使用OCRFlux吗?官方推荐至少12GB显存。如果显存不足,模型可能无法完整加载,或者在处理高分辨率页面时会因内存不足而出错。对于小显存用户,可以尝试减小模型的上下文长度限制或降低页面渲染的分辨率,但这可能会影响解析效果。
- OCRFlux能处理手写文字吗?OCRFlux主要设计用于处理印刷体PDF文档和图像。对于清晰、规范的手写体可能有一定的识别能力,但其核心优势在于文档布局分析和结构化文本提取,而不是手写识别(Handwritten Text Recognition, HTR)。
- 相比于其他OCR工具,OCRFlux最大的优势是什么?最大的优势在于其基于大型多模态模型,对文档
结构的理解能力非常强。它不仅仅是识别文字,更能理解文字、表格、段落之间的关系。因此,它在处理多栏布局、跨页表格和段落这些复杂场景时,效果远超传统的OCR工具,能够生成更符合人类阅读习惯的干净Markdown文本。